StackEval: Benchmarking LLMs in Coding Assistance
Most coding benchmarks still emphasize problems that are easy to unit test. That usually means narrow code generation or completion tasks with clean success criteria. Those benchmarks are useful, but they miss a large share of how coding assistants are actually used.
In practice, a lot of coding assistance is natural-language Q&A: debugging an error, explaining unfamiliar behavior, comparing implementation options, or helping a developer get unstuck in an unfamiliar stack. That kind of support is harder to evaluate, precisely because it is less neatly unit testable, but it is also much closer to real developer workflows.
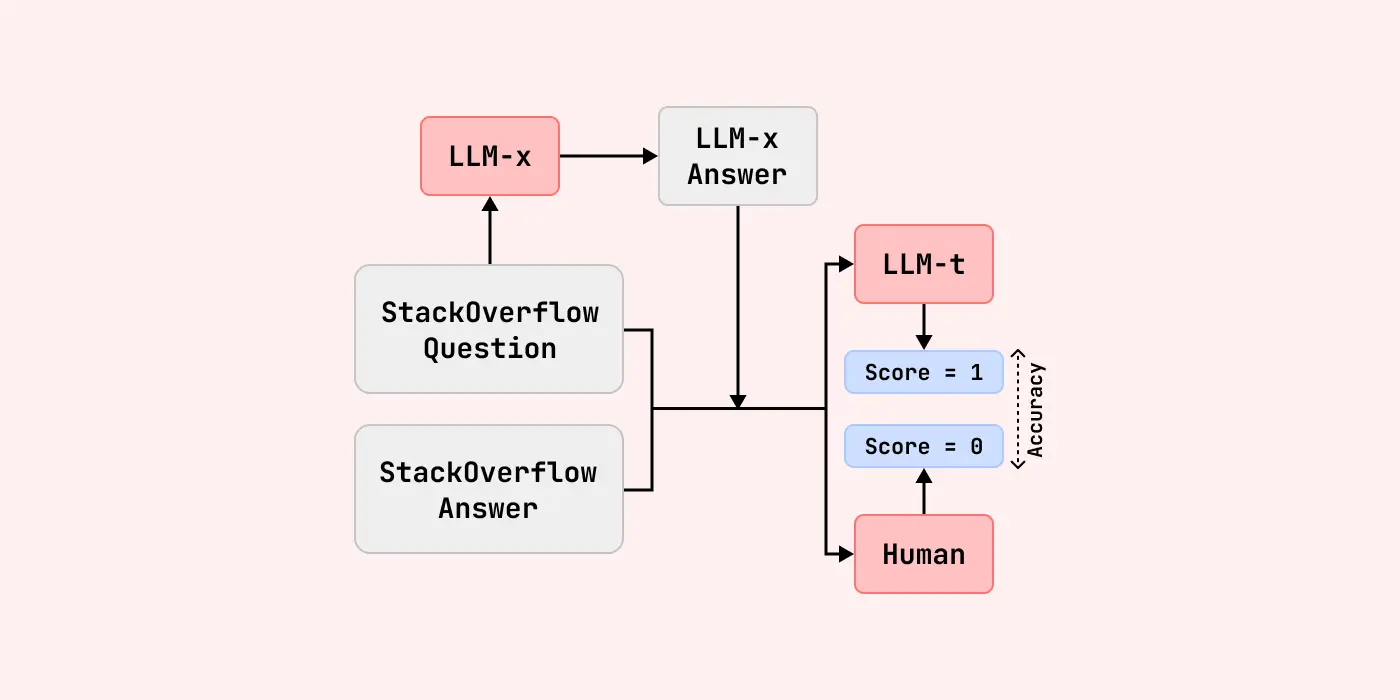
That gap is what motivated our paper, StackEval: Benchmarking LLMs in Coding Assistance. StackEval is built around real coding-assistance tasks drawn from practice, including debugging, implementation, optimization, and conceptual understanding across many programming languages. The goal is not just to measure whether a model can produce code, but whether it can provide help that is actually useful.
One important part of the benchmark is StackUnseen, which evaluates models on newer Stack Overflow questions. This matters because coding changes quickly. Frameworks evolve, APIs get replaced, best practices shift, and new developer pain points appear all the time. A model that performs well on older benchmark data may still struggle when the question reflects a newer toolchain or a more current development pattern.
More broadly, this connects to the direction behind ProLLM: benchmarks should be useful, reliable, and tied to real-world use cases. If a benchmark mostly rewards what is easy to score rather than what is valuable in practice, it becomes much less useful for model selection or product decisions. That is especially true for coding, where small differences in usefulness can have a large impact on developer productivity.
StackEval is one step toward more practical evaluation for coding assistants, and hopefully a useful resource for both researchers and product teams building with LLMs. You can read the full paper here: arXiv:2412.05288.